2026
 ECCV
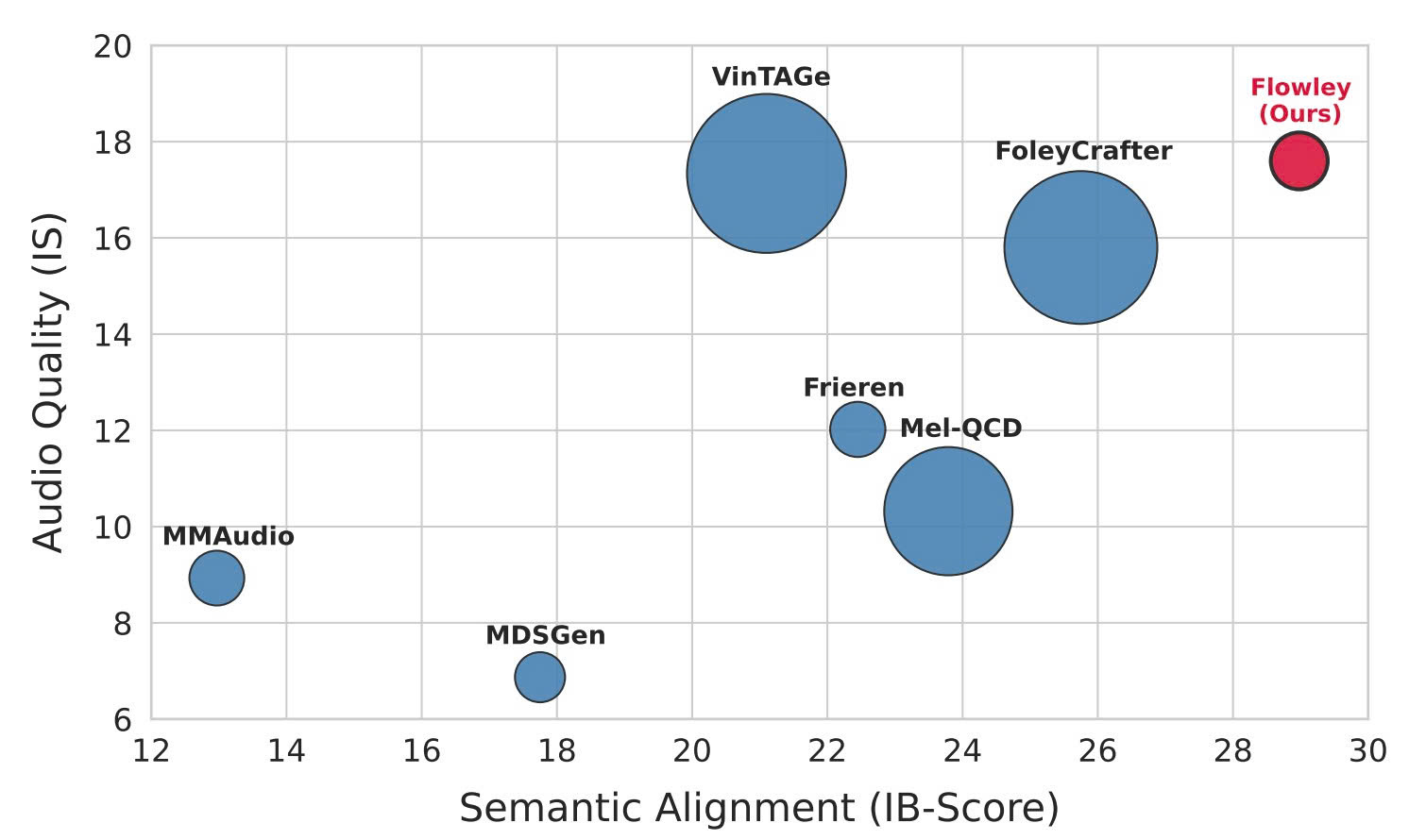
ECCVPrecise Video-to-Audio Generation with Cross-Modal Alignment in Latent Space
Thanh V. T. Tran, Ngoc-Son Nguyen, Luong Tran, Long-Khanh Pham, Paarth Neekhara, Shehzeen Samarah Hussain, Van Nguyen
The 19th European Conference on Computer Vision (ECCV) 2026
ECCV
 Interspeech
Interspeech
 CVPR
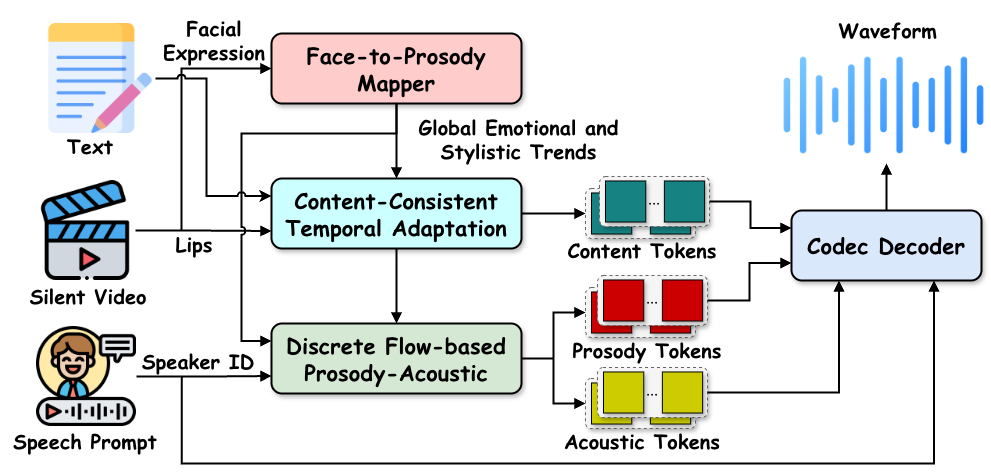
CVPRDiFlowDubber: Discrete Flow Matching for Automated Video Dubbing via Cross-Modal Alignment and Synchronization
Ngoc-Son Nguyen, Thanh V. T. Tran, Jeongsoo Choi, Hieu-Nghia Huynh-Nguyen, Truong-Son Hy, Van Nguyen
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Findings 2026
Also accepted at CVPR 2026 Workshop: "Sight and Sound"
CVPR
2025
 TMLR
TMLR
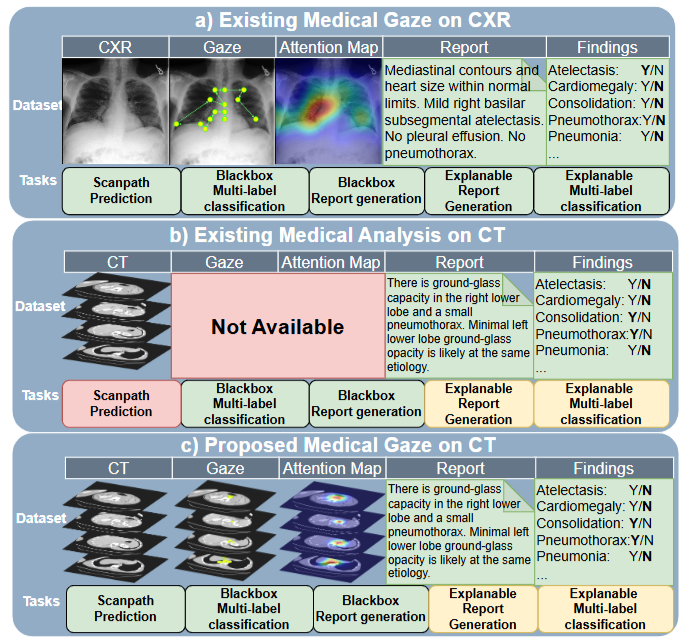 ICCV
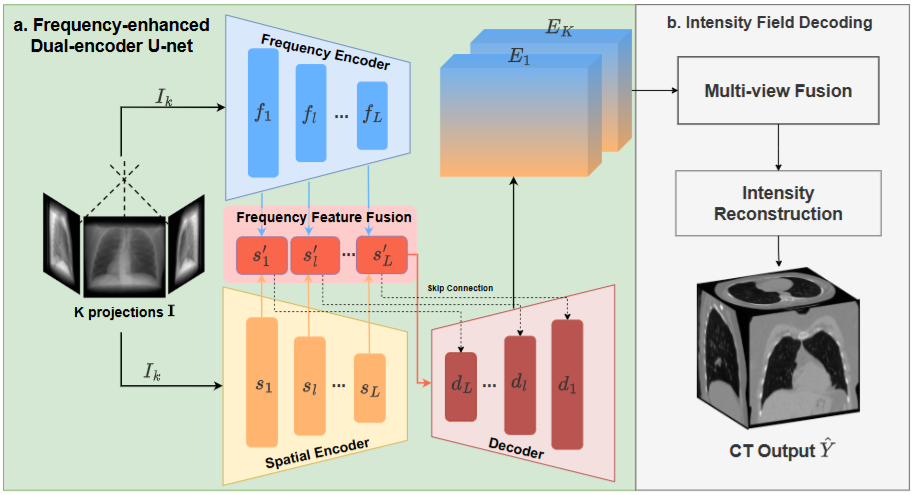
ICCVCT-ScanGaze: A Dataset and Baselines for 3D Volumetric Scanpath Modeling
Trong Thang Pham, Akash Awasthi, Saba Khan, Esteban Duran Marti, Tien-Phat Nguyen, Khoa Vo, Minh Tran, Ngoc-Son Nguyen, Cuong Tran, Yuki Ikebe, Anh Totti Nguyen, Anh Nguyen, Zhigang Deng, Carol C Wu, Hien Nguyen, Ngan Le
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2025 Highlight
ICCV
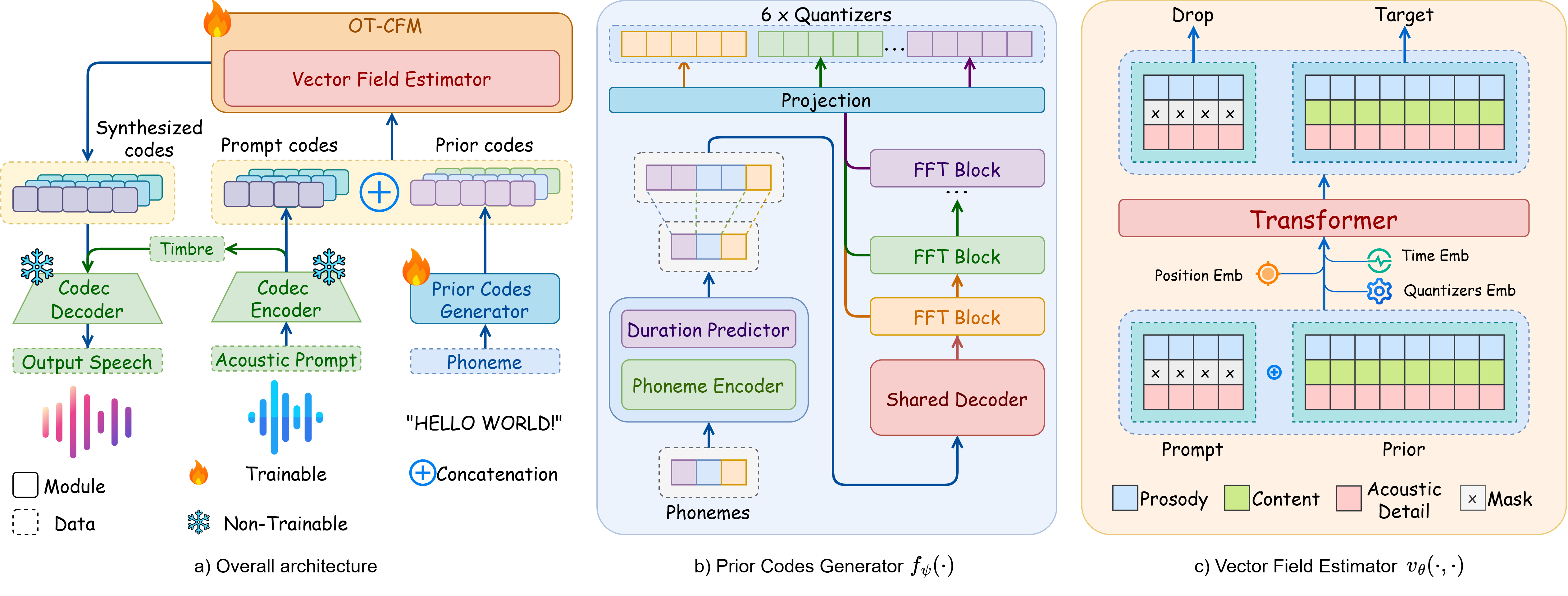 ACL
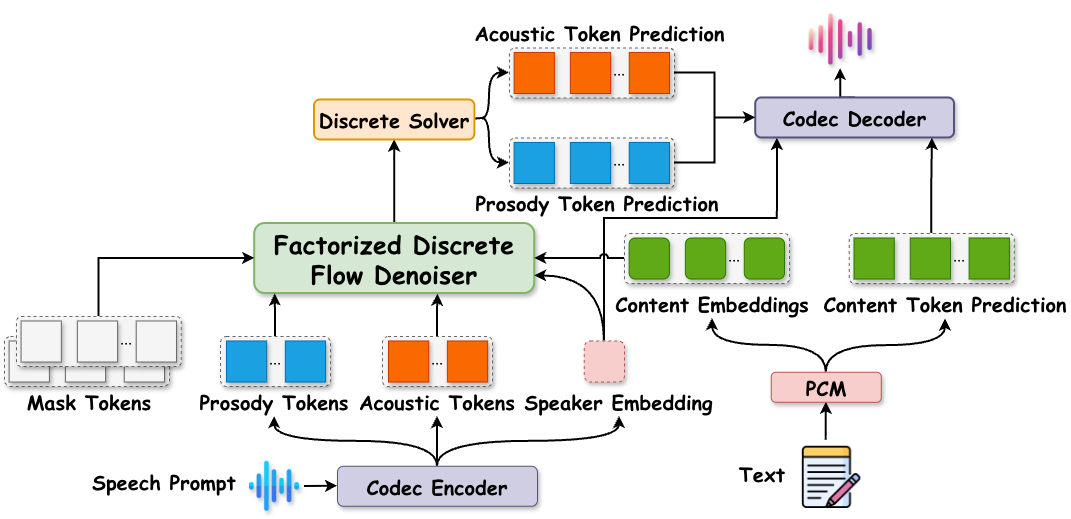
ACLOZSpeech: One-step Zero-shot Speech Synthesis with Learned-Prior-Conditioned Flow Matching
Nghia Huynh Nguyen Hieu, Ngoc-Son Nguyen, Huynh Nguyen Dang, Thieu Vo, Truong-Son Hy, Van Nguyen
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) 2025
ACL
2024
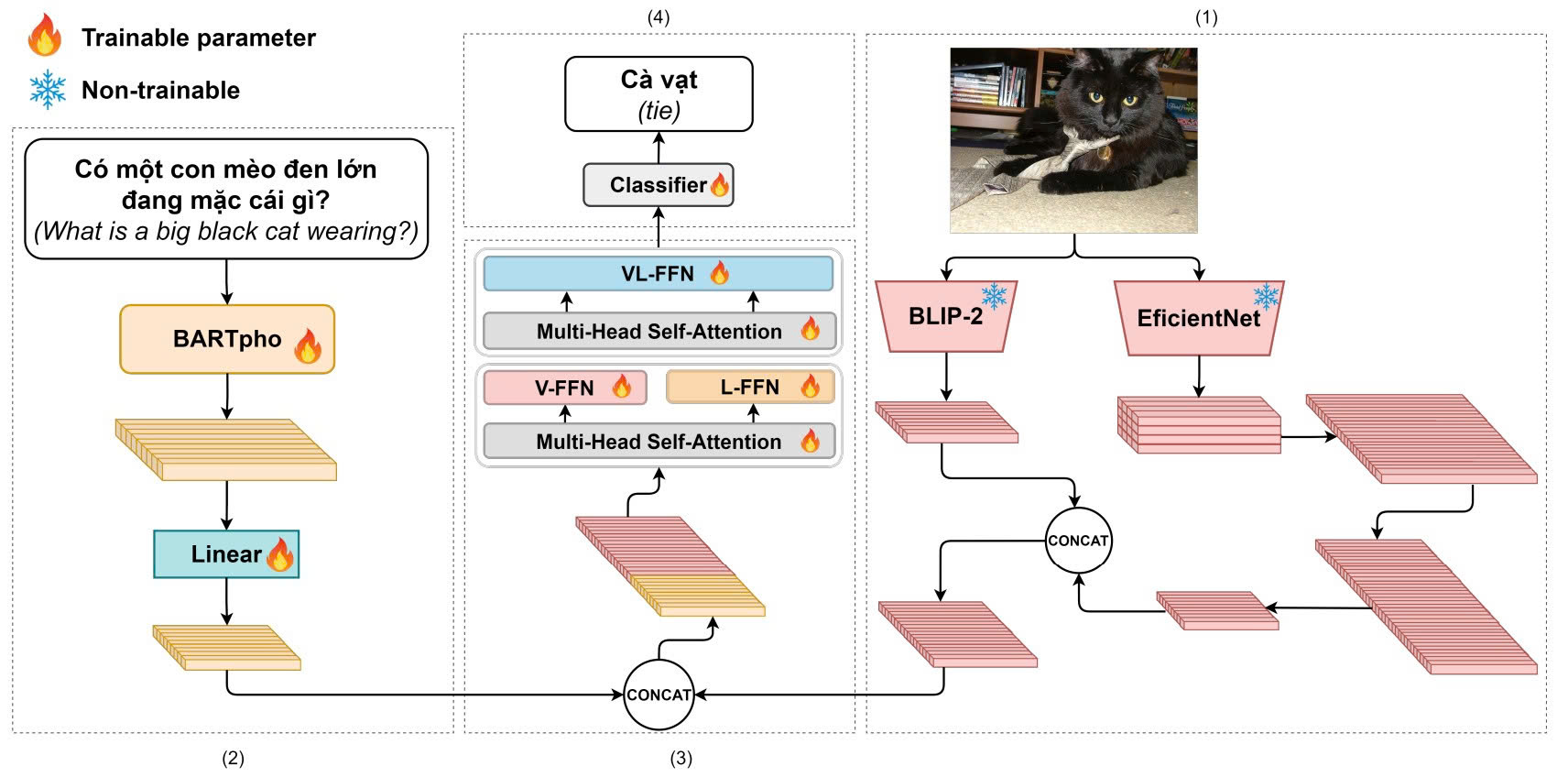 Elsevier Journal
Elsevier Journal
Preprints & Under Review
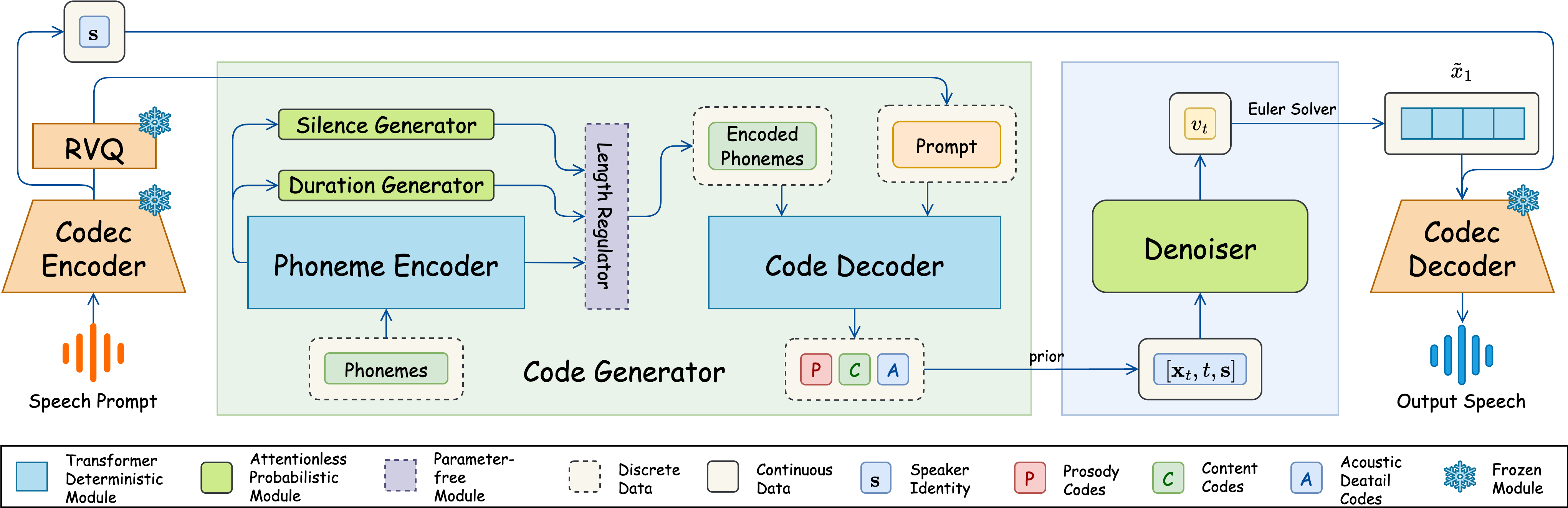 Under Review
Under Review
 arXiv
arXiv